라마 인덱스 (LlamaIndex) 란? RAG 최적화를 위한 핵심 도구
최근 RAG(검색 증강 생성) 기술이 자연어 처리 분야에서 큰 주목을 받고 있습니다. RAG는 방대한 외부 지식을 활용하여 Large Language Model(LLM)의 성능을 크게 향상시킬 수 있기 때문인데요. 하지만 RAG 파이프라인을 직접 구축하려면 데이터 로딩부터 인덱싱, 검색, 프롬프트 생성 등 복잡한 과정이 필요합니다.
이러한 어려움을 해결하기 위해 등장한 것이 바로 LlamaIndex입니다. 이 가이드에서는 LlamaIndex의 주요 개념과 사용 방법을 실습을 통해 자세히 알아보겠습니다.
라마 인덱스 (LlamaIndex) 란?
LlamaIndex는 RAG(Retrieval-Augmented Generation) 작업흐름을 간단한 Python 코드로 구현할 수 있게 해주는 강력한 오픈소스 라이브러리입니다. RAG는 외부 데이터를 LLM에 주입해 더 정확하고 최신의 응답을 생성할 수 있게 해주는 기술로, LlamaIndex는 이러한 RAG 파이프라인을 쉽고 효과적으로 구현할 수 있게 해줍니다.
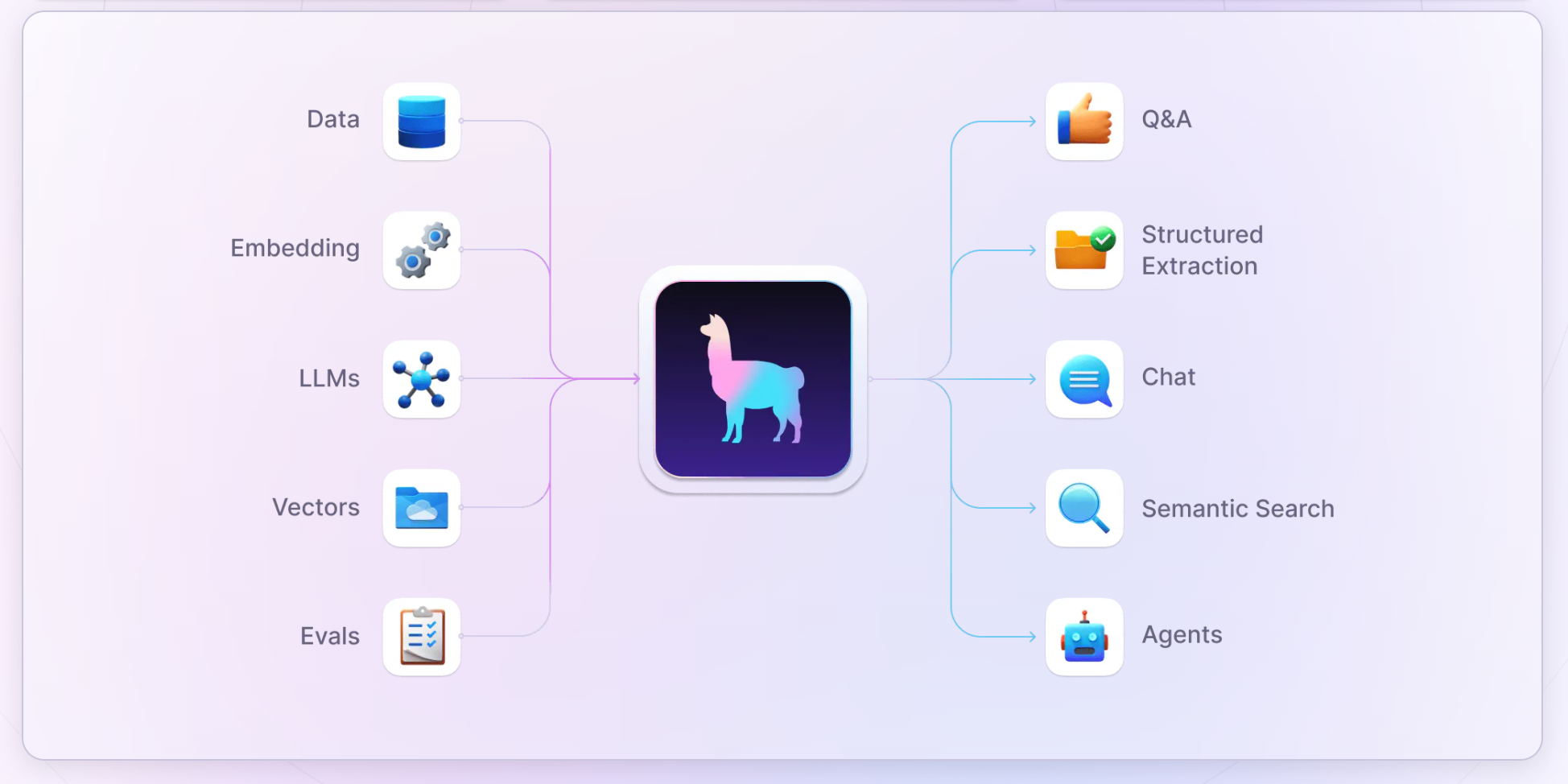
라마 인덱스 (LlamaIndex) 주요 기능
LlamaIndex의 주요 기능은 다음과 같습니다:
-
다양한 데이터 소스 지원: 텍스트, PDF, 웹사이트, API, 데이터베이스 등 다양한 형식의 데이터 소스로부터 데이터를 쉽게 로드할 수 있습니다.
-
데이터 인덱싱: 로드한 데이터를 벡터 임베딩으로 변환하고 효율적인 검색을 위해 인덱싱합니이를 통해 대규모 데이터셋에서도 빠른 검색이 가능합니다.
-
관련 문서 검색: 사용자의 쿼리에 대해 가장 관련성이 높은 문서나 데이터 조각을 검색합니다양한 검색 알고리즘을 지원하여 사용자의 요구에 맞는 검색 방식을 선택할 수 있습니다.
-
LLM 기반 응답 생성: 검색된 관련 문서를 바탕으로 LLM을 활용하여 사용자 쿼리에 대한 정확하고 상세한 응답을 생성합니다.
-
모듈화된 구조: LlamaIndex는 모듈화된 구조로 설계되어 있어, 사용자의 요구사항에 맞게 유연하게 확장이 가능합니각 컴포넌트를 필요에 따라 커스터마이즈하거나 교체할 수 있습니다.
-
다양한 백엔드 지원: 다양한 벡터 데이터베이스, 임베딩 모델, LLM 등을 지원하여 사용자가 원하는 환경에 쉽게 통합할 수 있습니다.
-
쿼리 최적화: 복잡�한 쿼리를 자동으로 분해하고 최적화하여 더 정확한 응답을 생성할 수 있습니다.
-
멀티모달 데이터 처리: 텍스트뿐만 아니라 이미지, 오디오 등 다양한 형태의 데이터를 처리할 수 있는 기능을 제공합니다.
LlamaIndex는 모듈화된 구조로 설계되어 사용자의 요구사항에 맞게 유연하게 확장 가능합니다. 또한 다양한 백엔드 DB, 임베딩 모델, LLM 등을 지원하여 원하는 환경에 쉽게 통합할 수 있습니다.
라마 인덱스 (LlamaIndex) 아키텍처
LlamaIndex를 효과적으로 사용하기 위해서는 몇 가지 핵심 개념을 이해해야 합니다.
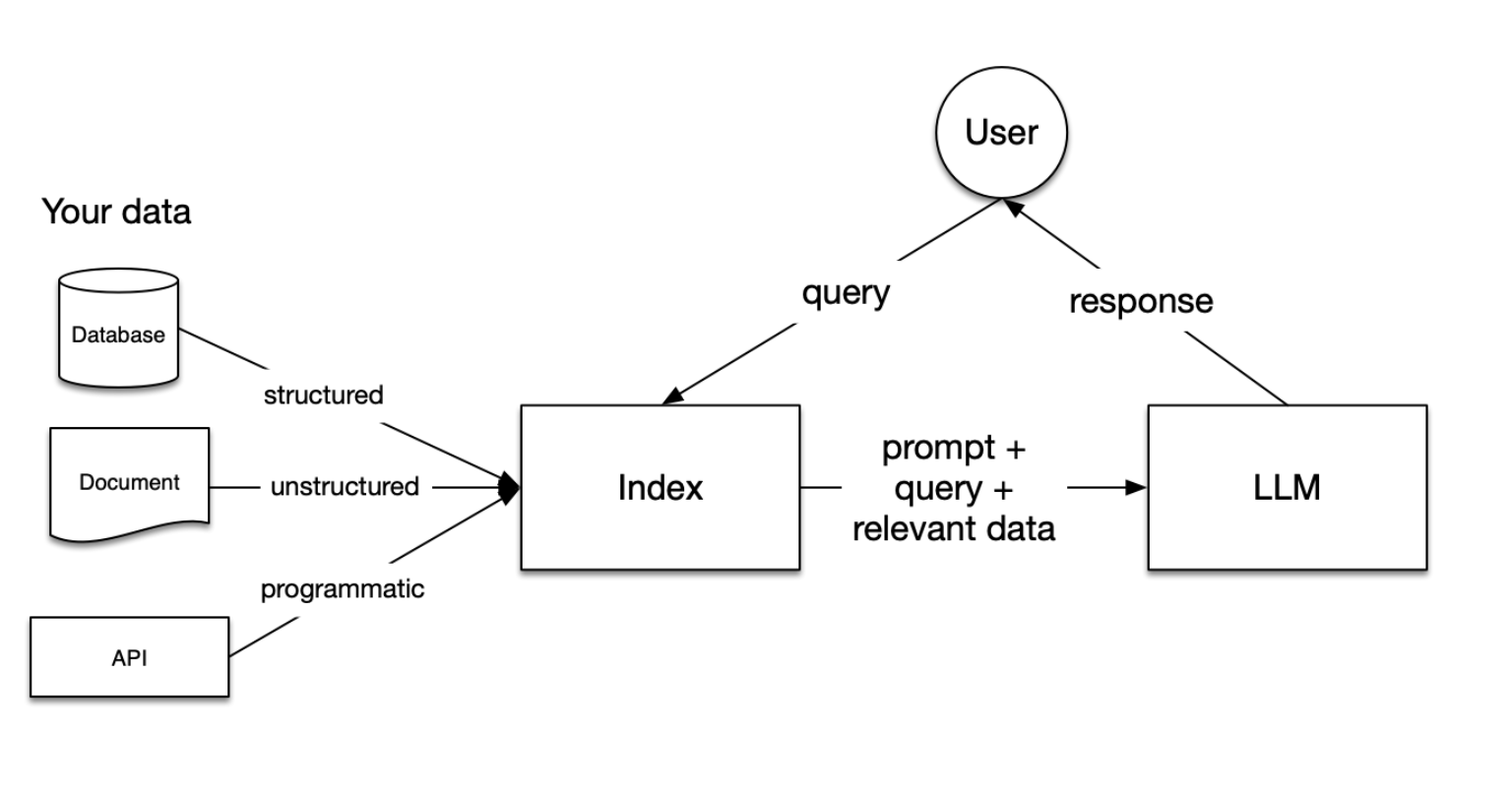
1) 인덱스 (Index) - 데이터 준비
여러분의 데이터는 다양한 형태(구조화된 데이터베이스, 비구조화된 문서, API 등)로 존재할 수 있습니다. 이 데이터는 "인덱스"라는 형태로 변환되어 쿼리에 사용될 수 있도록 준비됩니다.
2) 작업 요청: 사용자 쿼리
사용자가 질문을 입력하면, 이 쿼리는 인덱스에 전달됩니다.
3) 작업 요청 처리
- 관련 데이터 검색: 인덱스는 사용자의 쿼리와 가장 관련성 높은 데이터를 필터링합니다.
- 필터링된 관련 데이터, 원래 쿼리, 그리고 적절한 프롬프트가 LLM에 전달됩니다.
- LLM은 이 정보를 바탕으로 응답을 생성합니다.
- 생성된 응답이 사용자에게 전달됩니다.
이러한 개념들은 RAG(Retrieval Augmented Generation) 파이프라인의 각 단계와 밀접하게 연관되어 있습니다.
RAG 파이프라인의 주요 단계
RAG 파이프라인은 다음 5가지 주요 단계로 구성됩니다:
-
로딩(Loading): 다양한 소스(텍스트 파일, PDF, 웹사이트, 데이터베이스, API 등)에서 데이터를 가져와 파이프라인에 입력합니다. LlamaHub에서 제공하는 다양한 커넥터를 활용할 수 있습니다.
-
인덱싱(Indexing): 데이터를 쿼리 가능한 구조로 변환합니다. 주로
벡터 임베딩을 생성하여 데이터의 의미를 수치화하고, 관련 메타데이터를 함께 저장합니다. -
저장(Storing): 생성된 인덱스와 메타데이터를 저장하여 재사용할 수 있게 합니다.
-
쿼리(Querying): LLM과 LlamaIndex 데이터 구조를 활용하여 다양한 방식(서브쿼리, 다단계 쿼리, 하이브리드 전략 등)으로 데이터를 검색합니다.
-
평가(Evaluation): 파이프라인의 효과성을 객관적으로 측정합니다. 응답의 정확성, 충실도, 속도 등을 평가합니다.
LlamaIndex 실습
이제 LlamaIndex를 실습해보겠습니다. 아래 예제에서는 LlamaIndex를 사용하여 데이터를 로드하고 인덱싱한 뒤, LLM을 활용하여 질의에 대한 응답을 생성하는 과정을 살펴보겠습니다.
설치
우선 LlamaIndex를 설치합니다:
pip install llama-index
OpenAI API key를 환경변수로 설정합니다:
export OPENAI_API_KEY={YOUR_API_KEY}
데이터 로드 및 인덱스 생성
data 폴더에 원하는 데이터를 넣은 뒤 다음 코드를 실행하면 인덱스가 생성됩니다:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
쿼리 실행
생성된 인덱스에 대해 질의를 수행합니다:
query_engine = index.as_query_engine()
response = query_engine.query("원하는 질문을 입력하세요")
print(response)
LLM이 인덱스에서 검색된 관련 문서를 바탕으로 질문에 답변을 생성하게 됩니다. 더 자세한 내용이 궁금하다면 LlamaIndex 공식 문서에서 확인할 수 있습니다.
정리
LlamaIndex는 최신 RAG 기술을 손쉽게 활용할 수 있게 해주는 강력한 도구입니다. 이 가이드에서 살펴본 개념과 예제를 바탕으로 여러분만의 RAG 애플리케이션을 빠르게 구축해 보시기 바랍니다. LlamaIndex를 활용하면 방대한 데이터에서 원하는 정보를 정확하게 추출하고, LLM과 결합하여 다양한 자연어 처리 태스크를 수행할 수 있습니다.
LlamaIndex 생태계는 계속해서 발전하고 있으며, 새로운 기능과 모델이 지속적으로 추가되고 있습니다. 앞으로도 LlamaIndex가 RAG 분야의 혁신을 이끌어 갈 것으로 기대됩니다. 이 글이 여러분의 RAG 개발 여정에 도움이 되��길 바라며, 궁금한 점이 있다면 언제든 LlamaIndex 커뮤니티에 문의 바랍니다.